【3位解法】ProbSpace開催「宗教画テーマの分類」の振り返り。
データ分析好きが集まる交流プラットフォーム「ProbSpace」で開催された「宗教画テーマの分類」に参加し、3位の成績を残せました!
今回のコンペは、私の好きな画像分類のタスクだったので、結果も残せてよかったです。
また、画像分類のタスクでも、プロ野球データ分析チャレンジで使った、多値分類に2値分類を応用する戦法が活用できたのもよい経験でした。

では、振り返って参りたいと思います。
1.全体構成
今回のコンペは、米・メトロポリタン美術館が公開している、キリスト教の宗教画画像を、「受胎告知」、「最後の晩餐」など、13種類のテーマに分類するという画像分類コンペでした。
データの特徴として、訓練データが654枚、テストデータが497枚と、比較的データ量が少ないデータだったので、今回のコンペで許容された学習済みモデルをいかに活用できるかがポイントになりました。
また、今回も前回のプロ野球データ分析チャレンジと同様、分類するクラスごとの数に偏りがあったため、画像分類の処理を行った後、2値分類で精度を上げて上書きする処理を実施しました。
<データの分布>
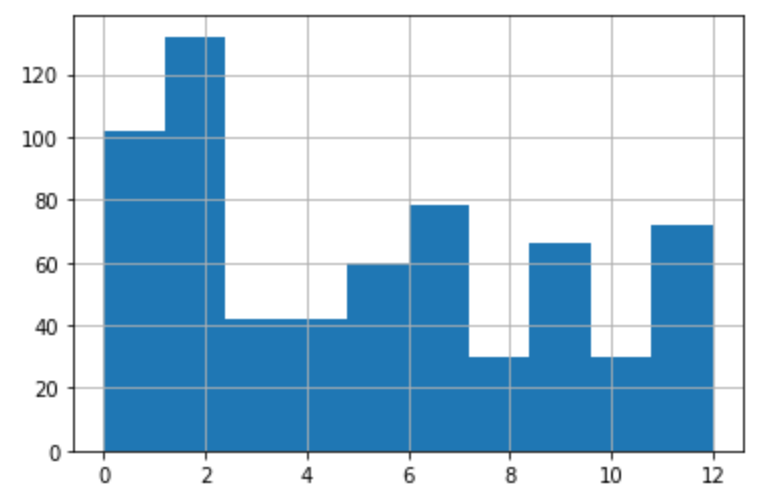
少ないデータ量を補うために、以下の対策を実施いたしました。
- 前処理:垂直・水平に反転した画像、回転した画像、セピア色に変換した画像を水増しした訓練データを作成。それぞれの画像の水増し割合を16パターンで学習を実施。
- モデル1段目:学習済みのEfficientNetを活用してファインチューニングを実施。
- モデル2段目:全クラスを予測する多値分類のモデルと、クラスごとの2値分類を実施するモデルを作成して、最後に上書きを実施。
また、ProbSpaceのトピックで公開させていただいたデータ内の画像の重複について(簡易自動化バージョン)を使って、重複・類似した画像を調べました。
2.前処理
前処理については、以下の2通りで実施いたしました。
データの前処理については、albumentationsというライブラリを利用しました。
【前処理 共通】
こちらは、訓練データ、テストデータの両方に適用する共通の処理です。
|
前処理 |
処理内容 |
|---|---|
|
サイズ変更 |
albumentationsのResize()を使って、画像サイズの変更を実施。後続の学習済みモデルに合わせたサイズに変更。 |
| 標準化 |
albumentationsのNormalize()を使って、画素値の標準化を実施。 |
【前処理 水増し】
こちらは、訓練データを水増しするために実施する前処理です。テストデータには実施しません。
|
前処理 |
処理内容 |
|---|---|
| 水平反転 |
albumentationsのHorizontalFlipを使って、指定した割合の画像を水平反転。 |
|
垂直反転 |
albumentationsのVerticalFlipを使って、指定した割合の画像を垂直反転。 |
| 回転 | albumentationsのRotateを使って、指定した割合の画像を回転。 |
| セピア変換 | albumentationsのToSepiaを使って、指定した割合の画像をセピア色に変換。今回のデータでは、古い絵画もあったので、採用してみました。 |
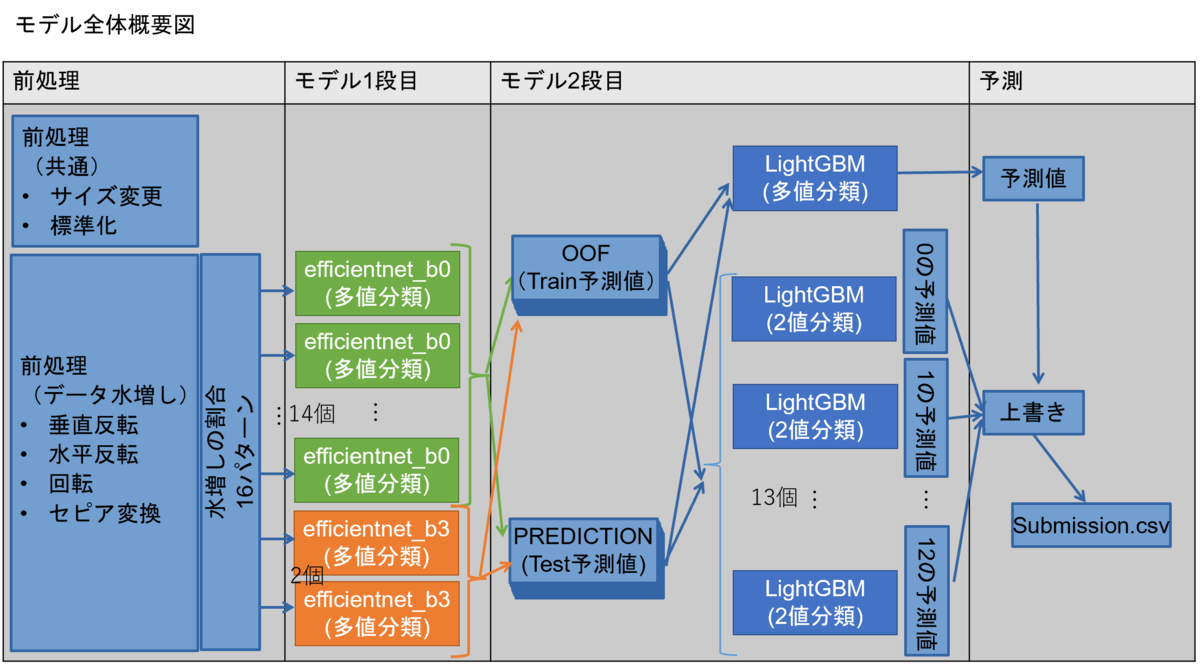
3.モデル構築
今回は、大きく分けて、「学習済みのEfficientNetを活用してファインチューニングを実施」する1段目と、プロ野球データ分析チャレンジで使った、「全クラスを予測する多値分類のモデル」の出力に、「クラスごとの2値分類を実施するモデル」の出力を上書きをする2段目を組み合わせた、スタッキングモデルを構築しました。
【1段目:EfficientNet】
1段目は、EfficientNetの学習済みモデルをファインチューニングして、2段目に渡す訓練データの予測値と、テストデータの予測値を出力するモデルを16個作成しました。
それぞれのモデルで、訓練データの水増しの割合を変更することで、パターン分けしました。
このモデルは、skywalkerさんがトピックに投稿してくださっている、EfficientNetB0使ったベースラインも参考にさせていただきました。
このモデルの学習には、GPUが必要となるので、Google Colabで実行するには、実行時間に制約があるので、とても骨が折れました。
【2段目:LighetGBM】
2段目は、16種類の予測値を訓練データとして、「多値分類するモデルの予測値」に、「各分類ごとの2値分類をするモデルの予測値」を上書きすることで、精度を上げる方法を実施しました。
この方法は、プロ野球データ分析チャレンジで採用した方法を応用しました。
今回も、通算500個以上のモデルを作って、いろいろな組み合わせを試し、そのうち200回以上の提出を実施しました。後半はほぼ毎日提出しました。
4.感想
今回のコンペは、宗教画の意味するテーマを分類するコンペでした。
これまで、宗教画をじっくり眺めて、テーマを考えることがなかったので、「あ、この絵のこの部分はこういうことを表しているんだ。」と、モデル以上に自分自身も学習することができました。(笑)
途中、自分が分類する場合に、「十字架があるな」、「人が多いな」などを基準にしたりするので、物体検出が応用できないかと、Yoloにも挑戦してみましたが、なかなか精度は上がりませんでした。
参考:学習済みのYOLOv5による物体検出結果の特徴量への追加
新しい技術にも触れられて、とても有意義なコンペとなりました。
また、今回からProbSpaceでも、最終提出ファイル選択方式となったので、最後の最後まで、ファイル選びに悩みました。
Public:Privateが13%:87%と、Publicスコアがあまり重視できない割合だったこともあって、ShakeDownしてしまいましたが、何とか3位になることができました。
5.謝辞
最後となってしまいましたが、本コンペを運営してくださいました、ProbSpace の運営の皆様、一緒にコンペに取り組んでいらっしゃった皆様、Twitter上でやりとりを実施させていただいた皆様に心より感謝申し上げます。
今回学ばせていただいた事項を糧に、社会貢献できるよう引き続き精進してまいりたいと思います。
【過去記事】
G検定、E資格の取得から、これまでに取り組んできた道のりは以下にまとめております。何かのご参考にしていただければ幸いです。