【1位解法】ProbSpace開催「プロ野球データ分析チャレンジ 」の振り返り。
データ分析好きが集まる交流プラットフォーム「ProbSpace」で開催された「次の一投の行方を予測! プロ野球データ分析チャレンジ」に参加し、1位の成績を残せました!
現在、オープンレビュー中のため、賞金獲得は未確定ですが、解法について公開させていただきます。確定できれば、昨年のNishika開催の「Jリーグプレイヤーの出場予測」(参考;【2位解法】Nishika開催「Jリーグプレイヤーの出場時間予測」の振り返り)に続き、スポーツ関連で2個目の賞金獲得になります。
また、今回1位が確定できれば、ProbSpace内で、トピック、コンペティション、総合の3分野で1位になることができます!
【後日談】無事オープンプレビューが完了し、優勝が確定しました!
2021年上半期+αの振り返り(機械学習の積み上げ~さらなる高みを目指して~)
今回のコンペは、様々な手法の前処理を適用するとともに、回帰、2値分類、多値分類の複数の種類のモデルを駆使し、持てる力を十二分に発揮することができました。
では、振り返って参りたいと思います。
1.全体構成
今回のコンペは、日本のプロ野球で、投げられた1球が、ストライクになったか、ヒットになったかなどの投球結果を予測するテーブルコンペでした。
データの特徴として、球速や、投げられたコースなどは、trainデータにしかなく、testデータから予測する際には、一度、testデータに不足している特徴量を予測するモデルで予測してからひと工夫が必要でした。
【trainデータにしかない特徴量】

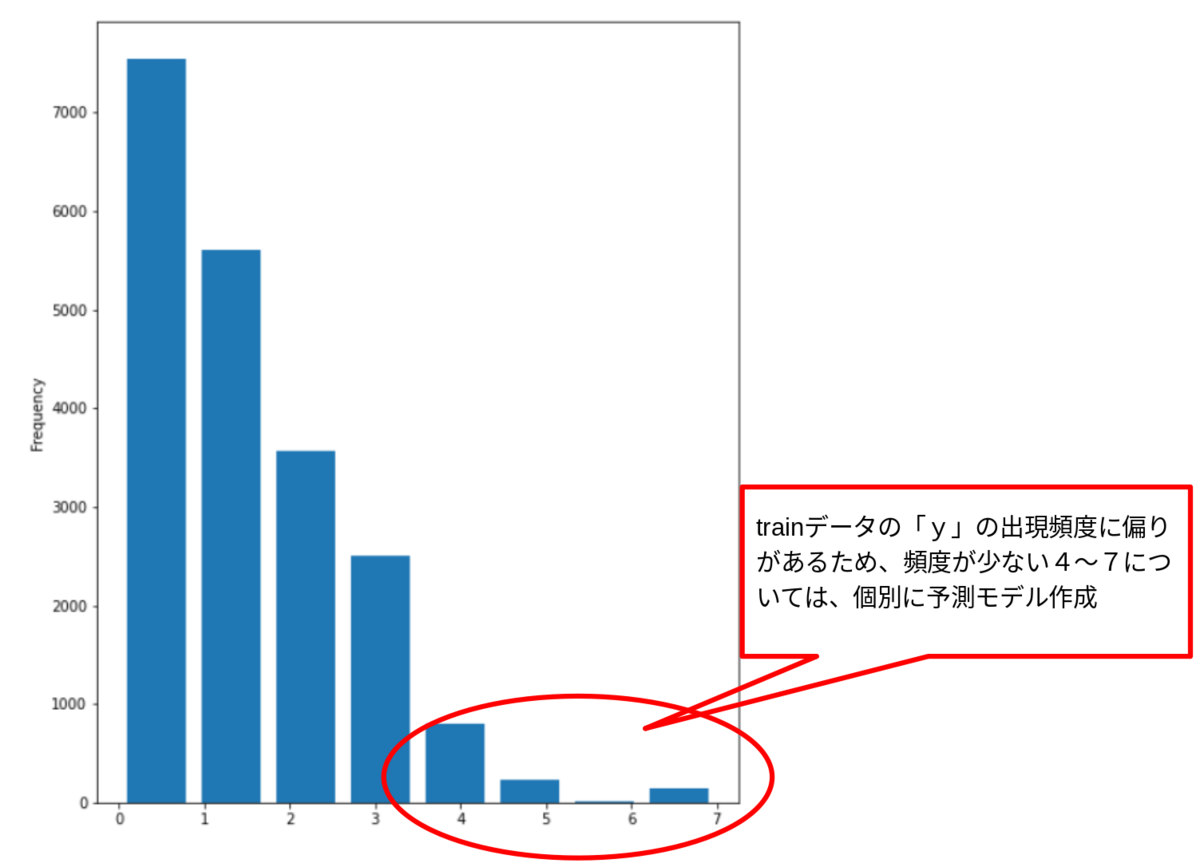
また、当然といえば当然なのですが、ストライクやボールに比べ、ヒット、2塁打、3塁打、ホームランの数が非常に少なく、分類されるデータ量が偏ったデータとなっていました。testデータも同様の分布になると過程し、数が少ない分類については、個別に予測モデルを作成することにしました。
【trainデータの「投球結果」の度数分布】
上記のような状況を踏まえ、最終的には以下のような構成のモデルを作成しました。
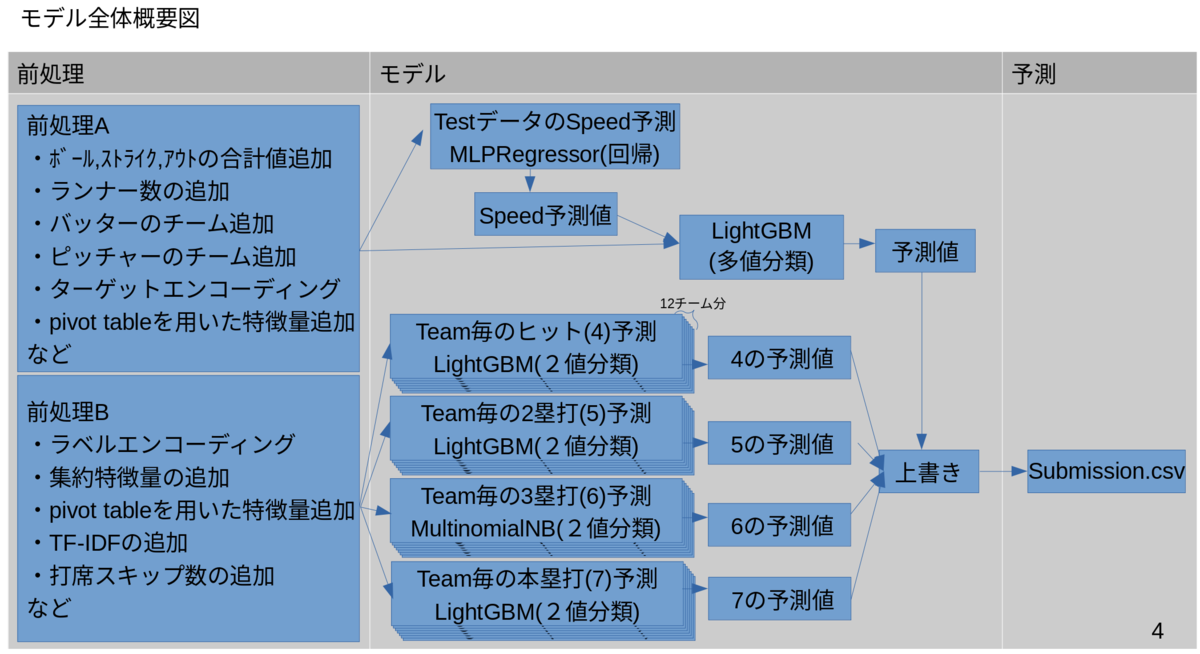
前処理済みのデータは2種類用意して、以下の2種類のモデルで予測し、多値分類を行った予測値に、頻度が少ない値を2値分類として予測し予測値を上書きすることで、最終的に提出する予測値を作成しました。
- trainにしかないSpeedの予測値をtestデータの特徴量に追加して多値分類を行うモデル
- その1球が「ヒットになるかならないか」、「2塁打になるかならないか」、「3塁打になるかならないか」、「本塁打になるかならないか」の2値分類を行うモデル
2.前処理
前処理については、以下の2通りで実施いたしました。
【前処理A】
こちらは、ProbSpaceのトピックで公開させていただいたベースラインの前処理となります。[トピックはこちら→改良版-LightGBM Base line−コメント付き (CV= 0.14834 / LB= 0.13733)]
|
前処理 |
処理内容 |
|---|---|
| 年月日、曜日、時分秒を追加 |
'startDayTime'から、試合の開始年月日、曜日、時分秒を作成してそれぞれを特徴量として追加。 |
|
回数と裏表を追加 |
'inning'から、回数と裏表を作成して、それぞれを特徴量として追加。 |
|
ボール、ストライク、アウトの合計値を追加 |
ボール、ストライク、アウトのカウントの合計値、およびボール、ストライクの合計値を特徴量として追加 |
|
ベース上のランナーの数を追加 |
1塁、2塁、3塁のベース上のランナー数の合計値を特徴量として追加 |
|
バッターのチームを追加 |
表の場合は'topTeam'を、裏の場合は'bottomTeam'を、バッターのチームとして追加 |
|
ピッチャーのチームを追加 |
表の場合は'bottomTeam'を、裏の場合は'topTeam'を、ピッチャーのチームとして追加 |
【カテゴリカル変数の処理】
|
前処理 |
処理内容 |
|---|---|
|
カテゴリカル変数をカウントエンコード |
xfeat の CountEncoder を使用して、各カテゴリ変数をカウントエンコードした特徴量を追加 |
| カテゴリカル変数をターゲットエンコード | xfeat の TargetEncoder を使用して、各カテゴリ変数をターゲットエンコードした特徴量を追加 |
【その他】
|
前処理 |
処理内容 |
|---|---|
|
pivot tabel を用いた特徴量を追加 |
Pandas の pivot_table を使用して、"gameID"をインデックスとした各種ピボットデータを特徴量として追加 |
【前処理B】
こちらは、ProbSpaceのトピックでDT-SNさんが公開してくださいましたベースラインの前処理となります。
詳細は、DT-SNさんが公開してくださったトピックをご参照ください。
[トピックはこちら→LightGBM Base line(CV=0.2228,LB=0.16746)]
3.モデル構築
今回は、大きく分けて、目的となる分類の全クラスを分類するモデルと、頻度の少ないヒット、2塁打、3塁打、ホームランのそれぞれを予測するモデルを作成いたしました。
【全体の多値分類】
前者は、2段階のモデルを組み合わせています。
1段階目は、前処理Aのデータを用いて、訓練データのみにあるspeedの特徴量をMLPRegressor(回帰)で予測するモデルを作成し、TestデータにもSpeedの特徴量を追加しました。
2段階目は、前処理AのデータにSpeedの特徴量を追加した特徴量からLightGBMで多値分類を行うモデルを作成しました。
【頻度の少ないクラスの2値分類】
後者は、ヒットになるかならないかの2値分類を行うモデル、2塁打になるかならないかの2値分類を行うモデル、3塁打になるかならないかの2値分類を行うモデル、ホームランになるかならないかの2値分類を行うモデルを、それぞれ作成しました。
2値分類については、過去にProbSpace実施された、「スパムメール判別コンペ」の1位解法で利用されていた「ダウンサンプリング」や「MultinomialNB」などを採用させていただいたり、「対戦ゲームデータ分析甲子園」で武器ごとの予測を試したことを応用して、チームごとの予測を採用したりしました。
最終的には、後者のそれぞれのモデルで「なる」に分類されたデータを前者のモデルでの予測値に上書きすることで、最終的な予測値としました。
(通算500個以上のモデルを作って、いろいろな組み合わせを試し、そのうち約170回の提出を実施しました。後半はほぼ毎日提出しました。)
4.感想
今回のコンペは、プロ野球選手の実名のデータが登場するコンペだったので、実際の状況を想像しながら楽しんで取り組むことができました。
野球は、スポーツの中でも戦略やゲーム性が高いスポーツなので、こういった分析が実際の試合でも使われていると考えると、これからますます機械学習が応用されるのではないかと感じました。
今回も、とにかくいろんなモデルを作成しては、出力を提出して、LBスコアを確認しながら、とりくみました。
コンペの前半で、多値分類のモデルだけでなく、出現頻度の低いクラスについては、2値分類のモデルを採用することを思いついたことが、スコアの向上に大きく貢献しました。
2値分類については、過去いろいろなのコンペで取り組んでいたので、これまでの資産が十分に効果を発揮しました。改めて、コンペ毎に完結するのではなく、コンペで培った資産は、次に活かしていくことも大切と感じました。
また、今回は、Open Review Competitionということで、公開することも考慮しながらコードを作成いたしました。途中で、トピックにベースラインを公開して、皆さんのご指摘もいただきながら修正して、なんとか提出ができました。
あとは、レビュー結果が楽しみです。
5.謝辞
最後となってしまいましたが、本コンペを運営してくださいました、ProbSpace の運営の皆様、一緒にコンペに取り組んでいらっしゃった皆様、Twitter上でやりとりを実施させていただいた皆様に心より感謝申し上げます。
今回学ばせていただいた事項を糧に、社会貢献できるよう引き続き精進してまいりたいと思います。
【過去記事】
G検定、E資格の取得から、これまでに取り組んできた道のりは以下にまとめております。何かのご参考にしていただければ幸いです。