2021年上半期は、昨年に引き続き、機械学習の積み上げの成果を試すため、いろいろなデータ分析サイトのコンペティションに挑戦しました。
中でも、念願のKaggleでの初メダル獲得や、ProbSpaceでの初優勝など、自分内「初」の記録を残せた半期でした。
いろいろな制約があり、なかなか思うようにならないことが多いご時世ですが、自身のできることを、できる範囲でコツコツと進めてきた成果だと思っています。
引き続き、「ゆっくりでも止まらなければ結構進む」の精神で頑張って行きたいと思います。
【目次】
【コンペ関連】
1.Kaggleで初メダル獲得!(Cassava Leaf Disease Classification)
2021年上半期で印象に残った出来事の1つ目は、念願のKaggleにて初メダルを獲得できたことになります。
2月に終了した鳥蛙コンペ(Rainforest Connection Species Audio Detection)では、善戦したものの、Top16%でメダル獲得ならずだったのですが、直後に結果がでたタロイモコンペ(Cassava Leaf Disease Classification)にて、Top6%に入ることができ、初の銅メダル獲得となりました!
残念だったのは、強化学習に本格的に取り組んだじゃんけんコンペ(Rock, Paper, Scissors)では、Top11%と、あと7つ上位に届かず、メダル&Expert昇格を逃してしまったことでした。
とはいえ、メダル獲得が夢ではなく手に届くところまできたのは、大きな進歩でした。
なんとか今年中に、もう一つメダルを獲得して、Expertを目指します!

2.ProbSpaceで初優勝!総合ランキング1位をキープ
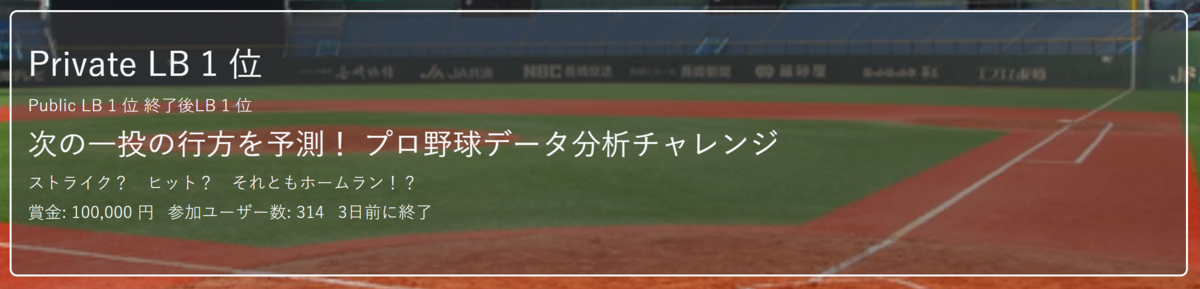
2021年上半期で印象に残ったもう一つの出来事は、データ分析プラットフォームProbspaceで開催された、プロ野球データ分析チャレンジで、初優勝できたことでした。これまで、コンペで2位や3位になったことはあったのですが、優勝は初めてだったので、感無量でした。
また、3月に終了した、論文の被引用数予測コンペでは、41位と散々な成績だっただけに、喜びもひとしおでした。
この優勝で、ProbSpace内ランキングにおいて、トピック、コンペティション、総合の3部門全部で1位を達成することができました。(総合ランキング)
各コンペでの記録は以下の通りです。
- 2021年1月〜3月 論文の被引用数予測コンペ 41位
- 2021年4月〜6月 プロ野球データ分析チャレンジ 優勝 金
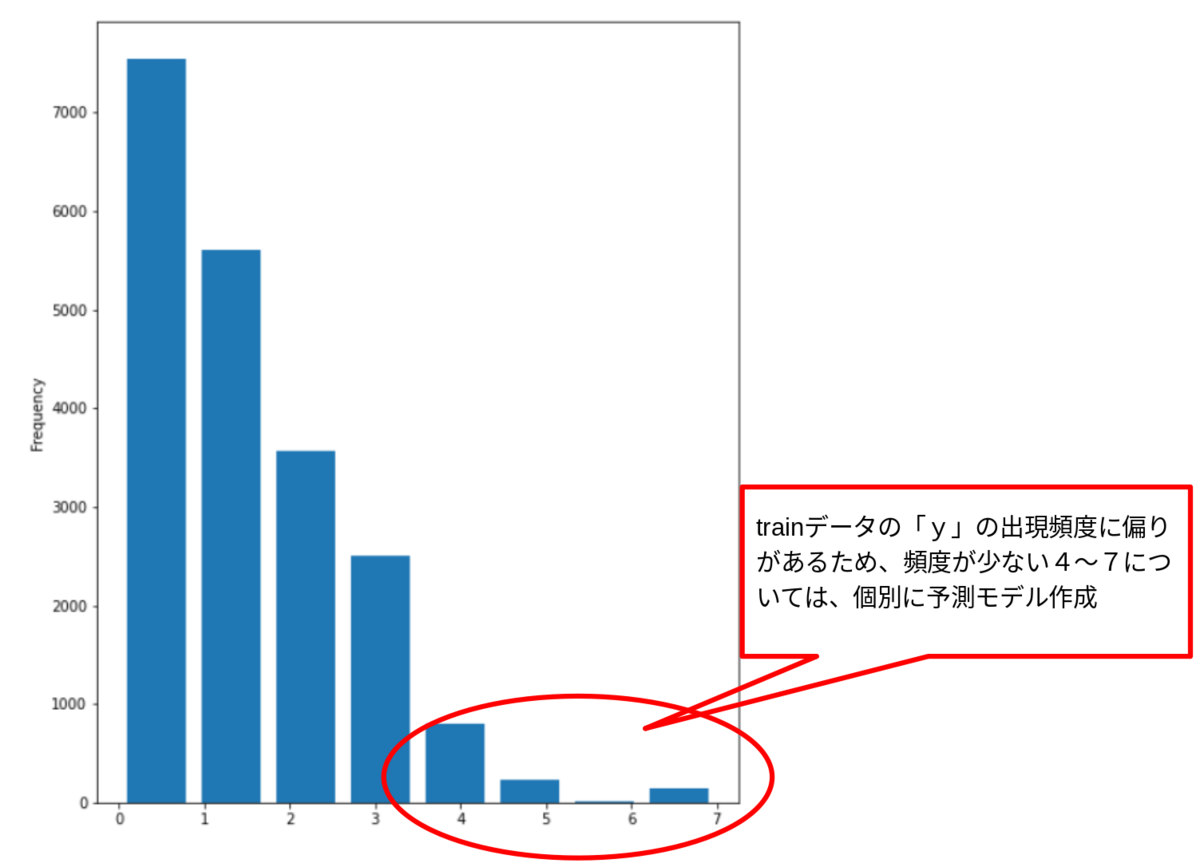
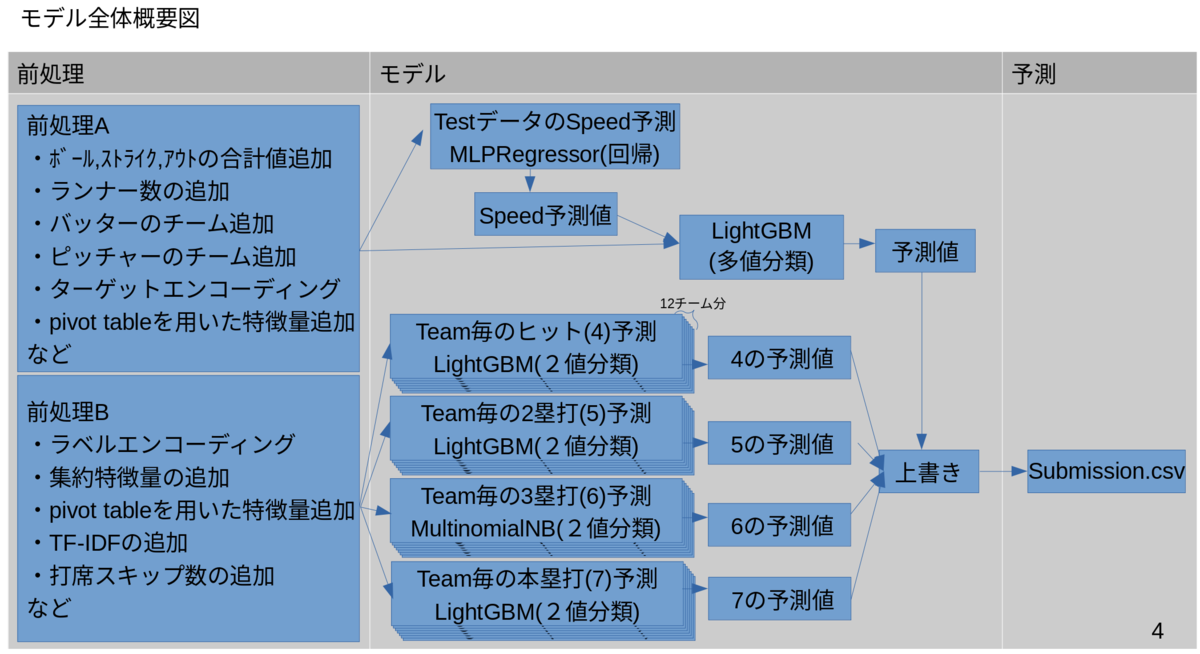
関連記事:【1位解法】ProbSpace開催「プロ野球データ分析チャレンジ 」の振り返り。


3.Solafune、Nishikaで宇宙・航空系コンペに挑戦
宇宙・航空系に興味をもっている私は、宇宙・航空系のコンペにも参加しました。
具体的には、衛星データ分析サイトのSolafuneで開催された「夜間光データから土地価格を予測」、データサイエンスコンペティションサイトのNishikaで開催された「航空機ターボエンジンの残存耐用時間予測」の2つに挑戦し、以下の結果を残すことができました。
- 2020年12月〜2021年4月 Solafune 夜間光データから土地価格予測 9位
関連記事:【9位解法】Solafune開催「夜間光データから土地価格を予測」の振り返り。 - 2021年7月 航空機ターボエンジンの残存耐用時間予測 10位
また、昨年から宇宙関連のコンペに参加していたこともあり、宇宙関連の情報サイト宙畑さんの取材を受け、以下の記事にしていただけました。
Kaggle では、まだまだヒヨッコなので、ランカーというのはお恥ずかしい限りなのですが、良い経験をさせていただきました。
【積み上げ関連】
1.AIQuest2020受講(〜2021年2月)
経済産業省が実施しているAI Quest 2020|SIGNATEに昨年から参加し、無事終了することができました。

守秘義務があり、詳細は記載できませんが、要件定義あり、コンペ形式でのAI開発あり、経営層向けのプレゼンありで、実業務に即した、かなり濃厚な講座でした。
結果としては、以下の通り、第1タームAI課題優秀賞&総合賞、第2タームプレゼン課題優秀賞&総合賞の表彰を受けることができました。

2.実践データサイエンスシリーズ(講談社サイエンティフィク)当選!
講談社サイエンティフィク (@kspub_kodansha) さんのキャンペーンに応募して、以下の3冊をちょうだいいたしました。
- 実践Data Scienceシリーズ PythonではじめるKaggleスタートブック (KS情報科学専門書) [ 石原 祥太郎 ]
- 実践Data Scienceシリーズ RとStanではじめる ベイズ統計モデリングによるデータ分析入門 (KS情報科学専門書) [ 馬場 真哉 ]
- 実践Data Scienceシリーズ データ分析のための データ可視化入門
Kaggleでの戦い方から、ベイズ統計モデル、データの可視化まで、実践を交えながら一通り学習できて、とても有意義な時間を過ごすことができました。
講談社サイエンティフィクの皆様ありがとうございました!

おわりに
2021年に入ってからも、引き続き、なかなか思うように活動できない日々が続いていますが、できる範囲の中で、チャレンジ精神を忘れずに、活発に行動していきたいと思います。
また、コンペに限らず、実社会でも貢献できるように引き続き精進してまいります。
さまざまなチャネルで、交流させていただいたり、繋がらせていただいたりしている皆様、本当にお世話になっております。
ささやかながら、皆様の活動の一助 となれるよう頑張ってまいりますので、今後ともよろしくお願いいたします。
【これまでの道のり】