前回に引き続き、日本ソフトウェア科学会機械学習工学研究会から2023年9月に公開された『機械学習システム セキュリティガイドライン Version 2.00』を数回に分けて、自分なりにゆっくり読み解いていきたいと思います。
今回は、『本編』の「I-2. 機械学習システム特有の攻撃」を読み解きました。
AIの開発や運用、サービス提供を行う皆さんの参考になる情報をご提供できればと思います。
また、G検定でも時事的な法律や制度などの問題も出題されているということなので、受験される方の何かの参考になれれば幸いです。
【目次】
1.ガイドライン全体の構成
『機械学習システムセキュリティガイドライン Version 2.00』は、付録も含めて、大きく三つに分かれています。機械学習システム特有の攻撃とその対策を説明した『本編』と、機械学習セキュリティの非専門家に向けた脅威分析・対策を記載した『リスク分析編』と、付録の『攻撃検知技術の概要』になります。
出所:機械学習システムセキュリティガイドライン Part I.「本編」
ページ[I-1]
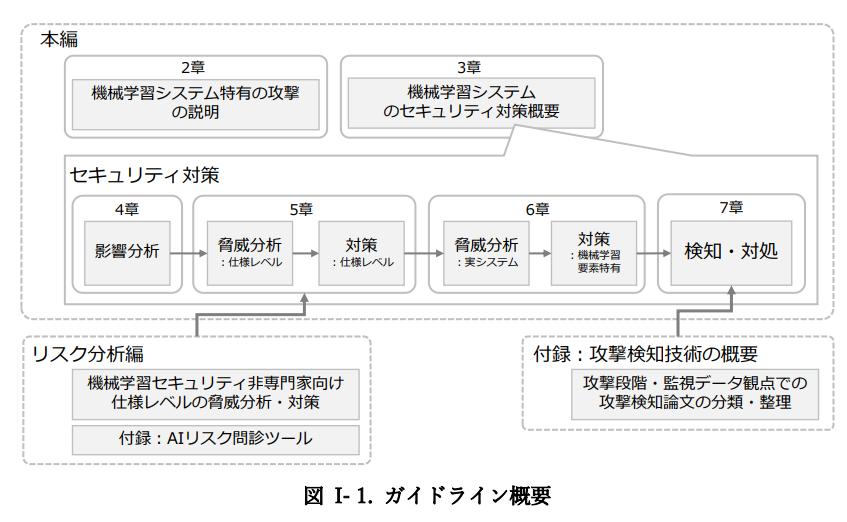
「I-1. ガイドライン概要」については、以下で記事にしておりますので、ご参照ください。
2.今回読んだ範囲の概要
今回は、『本編』の「I-2. 機械学習システム特有の攻撃」を読み解きました。
「機械学習システム特有の脅威 」、「脅威による被害例」、「脅威を引き起こす攻撃 」「攻撃方法 」について記載されています。
3.「I-2.1. 機械学習システム特有の脅威 」を読み解く
機械学習システムに特有の脅威は、以下の3つに分類され、これらは機械学習システムに対する正規の権限でのアクセスによって引き起こされる可能性もあると言及されています。
- モデルやシステムの誤動作
- モデルの窃取
- 訓練データの窃取
出所:機械学習システムセキュリティガイドライン Part I.「本編」
ページ[I-9]
「I-2.1.1. モデルやシステムの誤動作」では、機械学習システムのモデルを誤動作させ、システムに本来期待される動作が阻害される可能性があると言及されています。モデルやシステムの誤動作は、例えば自動運転システムの事故誘発やマルウェア検知の回避などの被害につながり得ます。攻撃手法としては、推論時のモデル・システムへの入力による攻撃や訓練データ・訓練モデルを汚染する攻撃が挙げられています。また、モデルやシステムの説明性機能だけを誤動作させることもあり、システムの透明性にも悪影響を与える可能性についても言及されています。
「I-2.1.2. モデルの窃取」では、機械学習システムのモデルのコピーまたは近い性能のモデルを攻撃者が作成するという脅威があげられています。モデルの窃取は、知的財産権への直接的な被害だけでなく、複製されたサービスや他の攻撃への被害にもつながり得ます。攻撃手法としては、モデルやシステムへの入力による攻撃が挙げられています。
「I-2.1.3. 訓練データの窃取」では、機械学習システムのモデルの訓練に使用されたデータそのものまたはその情報が攻撃者によって推測される脅威があげられています。被害としては、個人情報の漏洩などのプライバシー保護への被害が考えられます。攻撃手法としては、モデルやシステムへの入力による攻撃が挙げられています。
4.「I-2.2. 脅威による被害例」を読み解く
ここでは、前述の脅威について、発生の可能性がある事例と、それが起きた場合の想定被害をが説明されています。
| I-2.2.1. モデルやシステムの誤動作の脅威による被害例 | AIマルウェア対策製品がマルウェアを良性と誤認識すると、コンピュータへの不正侵入が可能になり、機密情報漏洩や損害が発生。損害額が膨大で、開発企業は損害賠償の可能性。 |
| I-2.2.2. モデルの窃取の脅威による被害例 | 近年AI開発において主流となっているMachine Learning as a Service (MLaaS) でのモデル複製により、本来の開発費用をかけずに競合他社が同じサービスを提供可能。モデルの複製による脆弱性悪用が引き金となり、追加被害の可能性。 |
| I-2.2.3. 訓練データの窃取の脅威による被害例 | 画像生成AIのキャプション工夫により、データ提供者の画像データが第三者に複製され、プライバシー侵害の可能性。特に医療情報の漏洩により、患者の精神的な被害と損害賠償のリスクが高まる。 |
5.「I-2.3. 脅威を引き起こす攻撃 」を読み解く
ここでは、前述の脅威について、脅威を引き起こす機械学習システム特有の攻撃として以下の代表的な5つの攻撃があげられています。
| I-2.3.1. 回避攻撃(evasion attack) | モデルやシステムの誤動作を引き起こす攻撃。入力データに微細な変更を加え、システムが予期せぬ動作をするように誘導。有名なのは敵対的サンプル攻撃で、微細なノイズを加えてモデルを誤判断させる。 |
| I-2.3.2. ポイズニング攻撃(poisoning attack) | モデルやシステムの誤動作を引き起こす攻撃。攻撃者が細工したデータやモデルを訓練データやモデルに混ぜ込み、誤動作を引き起こす。バックドア攻撃では特定のパターンが含まれた入力で誤判定。 |
| I-2.3.3. モデル抽出攻撃(model extraction attack) | モデルの窃取を引き起こす攻撃。機械学習システムへの入力と出力を分析して、同等の性能を持つモデルを作成する。モデルの知的財産を侵害する手法。 |
| I-2.3.4. モデルインバージョン攻撃(model inversion attack) | 訓練データの窃取を引き起こす攻撃。入力と出力を分析して、訓練データに含まれる情報を復元する。訓練データのプライバシー侵害が懸念される。 |
| I-2.3.5. メンバシップ推測攻撃(membership inference attack) | 訓練データの窃取を引き起こす攻撃。入力と出力を分析して、ある対象のデータがモデルの訓練データに含まれているかを特定する。データの所属を推測する攻撃。 |
6.「I-2.4. 攻撃方法」を読み解く
ここでは、攻撃者が有している知識や攻撃対象に依存して、攻撃方法が異なることに言及されています。
「I-2.4.1. 攻撃者の知識」について、前述の攻撃は、攻撃者の知識に基づいて、攻撃は他のシステムと同様にホワイトボックス攻撃とブラックボックス攻撃に分類される旨が記載されており、ホワイトボックス攻撃はモデルに関する内部情報を利用し、ブラックボックス攻撃は内部情報なしにモデルの入出力情報だけを使用すると定義されています。攻撃者が機械学習システムに関する情報を多く知っているほど、攻撃リスクが高まります。情報が公開されている場合や部分的な情報が流出した場合でも、注意が必要だとしています。
| 攻撃者の知識 | ホワイトボックス攻撃 | ブラックボックス攻撃 |
|---|---|---|
| 概要 | モデルの内部情報(アーキテクチャ、パラメータ、訓練方法など)を利用 | モデルの内部情報を用いず、入出力情報のみを使用 |
「I-2.4.2. 攻撃対象」について、物理ドメインとデジタル表現が挙げられています。物理ドメインとは実世界の情報をセンサーで取得し、デジタル化される前の状態です。デジタル表現とは情報がデジタル化された後の状態です。例えば、道路標識を認識するAIに対する攻撃として、特殊な模様のシール(敵対的パッチ)を標識に貼り付ける物理ドメインの攻撃や、デジタル表現の攻撃として、カメラで撮影されたデジタルデータにノイズを加えてAIを誤判定させる攻撃が挙げられています。
|
攻撃対象 |
物理ドメイン | デジタル表現 |
|---|---|---|
| 概要 | 実世界の情報を取得し、デジタル化される前の状態 | 情報がデジタル化された後の状態 |
| 例 | 特殊な模様のシールを物理的に標識に貼り付ける攻撃 | カメラで撮影されたデジタルデータにノイズを加える攻撃 |
7.おわりに
今回は、『機械学習システム セキュリティガイドライン Version 2.00』の『本編』の「I-2. 機械学習システム特有の攻撃」を読み解いてきました。
機械学習システム特有の攻撃として、正規の権限でのアクセスによって引き起こされる可能性がある点や、実世界情報がデジタル化される前の物理ドメインでの攻撃に留意する必要がある点について、他のシステムよりも十分注意が必要だと感じました。また、脆弱性パッチの適用の必要性やソーシャルエンジニアリング対応の必要性など、これまでのシステムのセキュリティの観点も応用できるのではないかと感じました。引き続き読み進めていきたいと思います。
では、次回は「I-3. 機械学習システムのセキュリティ」を読み解いていきたいと思います。





 4.感想
4.感想




